Although slightly better, still extremely difficult for visually impaired. Sadly the audio version is impossible to understand in most cases (example the audio and captcha for this comment is blank and when I downloaded the mp3 it was too distorted to hear) Accessibility should be of concern
Need to improve. some bot still can read it. maybe better if we can have some variation in number position. color and other custom things. so bot can not detect all. maybe they can detect the default, but with custom setting it will make more difficult
What's the point of a captcha? To determine if you're a human.
So... if you already know that I'm a human, why show the captcha in the first place? Unless the recaptcha system is really in place to just decipher the streetview photos of house numbers
btw, to leave this comment, I didn't get a numerical captcha. Am I a machine?
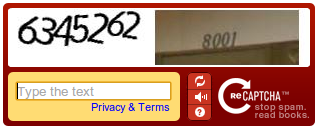
And obviously, the non-generated numbers are house/mailbox numbers from the Streetview database that Google wants to make semantic.
[EDIT: Solving a ReCAPTCHA to comment on an article about ReCAPTCHAs seems a bit too much of a good thing. :P 1642 utofio. Wavy words are not quite done with, it seems.]
The megatypers Captcha works awesome and pays well so do register and use the invitation code which is mandatory to register. Invitation CodeS : 7VF1 7VF2
Hi How can i make it only numeric we have used it in one site but the alphabets captacha is most of the time unreadable for many users can you tell the settings how to make it only numeric for making our life easy
Actually, the captchas are only easier if you have any cookies from Google. So its actually Google's way of punishing those that don't use their services.
Open up a private browser window and try a captcha, you'll know that they're significantly harder, not even difficult, they just automatically fail.
Actually, the captchas are only easier if you have any cookies from Google. Open up a private browser window, you'll notice that the captchas have black blobs in them and automatically fail.
If you're being tracked by Google's cookies, then the captchas are easier. If you're not being tracked, then its harder.
The example shown shows up on my home Mac using Safari. However, on my Windows PC using Internet Explorer at work I am now seeing words that are even more indecipherable than in the past (two words with a black ink blot over them). This is at the "Public PAIR" page of the USPTO.
I personally think this is too bad. The point of reCAPTCHA, beside detecting bots, is to improve OCR. Improving OCR for numbers is not that helpful (if that is what it is even doing, but I assume it does not) as improving OCR for letters and other characters. It was a very nice and helpful idea and this essentially ruins it. :(
I am confused - the text implies that form of captcha (numbers vs. twisted letters) depends on whether or not the system believes I am a human. But if the system already knows if I am a human, BEFORE I am presented a captcha, what is the point of showing it. Do I understand the term CAPTCHA ("Completely Automated Public Turing test to tell Computers and Humans Apart") in a wrong way?
I run a website for older people, and need to more closely hug the line in allowing bots through versus the clients. Through testing, it seems that if the system ever triggered to think the client is a bot then they would essentially become locked out of the system as the words would be too difficult for them.
If I'm understanding this correctly, in an attempt to block spam and bots, the captcha will also get increasingly difficult over multiple attempts while being testing by web designers tweaking their code eventually bringing testing to a halt!
Once reCAPTCHA (wrongly) determines you're a bot, you start being served challenges with two almost impossible to decipher random letter sequences (both of them "control words").
http://i.imgur.com/01F2eES.png
Maybe you think you can read this, but believe me, you can't. I tried "ryntrInt llyHFrv" on this particular one, and it was wrong. And they're all this bad. It takes me an average 10-15 tries to get one of them right, which of course means that I'll never get out of the "hole" of reCAPTCHA thinking that I'm a bot, because I fail so often.
I appreciated getting the easier, Street View captchas while I could still get them. But this adaptivity approach fails badly when going into the other direction (making challenges harder than classical reCAPTCHAs, rather than easier).
From my very limited dataset of just my own encounters, reCAPTCHAs human/bot pre-distinction is atrociously bad. And from my own horrible experiences with it, assuming that many of my own legitimate users will have to deal with the same, I've had no choice but to ditch reCAPTCHA entirely. I cannot afford to subject my users to this torture and scare them away forever. It's gone too far. Especially since I hear that there are bots out there with automatic captcha solvers that have a much better hit rate than myself at this point.
Any way to fix the issue whereby the big reCAPTCHA default logo is displayed, which makes users click on it because it includes a huge circle with arrows that makes people think that is the place to click on to reload a new set?
That logo has always been a big problem in terms of usability because it makes people click on it, rather than on the nearby very similar (but much smaller) reload symbol. I am surprised the issue is still there, as illustrated on top of this post.



34 comments :
Although slightly better, still extremely difficult for visually impaired. Sadly the audio version is impossible to understand in most cases (example the audio and captcha for this comment is blank and when I downloaded the mp3 it was too distorted to hear) Accessibility should be of concern
Need to improve. some bot still can read it. maybe better if we can have some variation in number position. color and other custom things. so bot can not detect all. maybe they can detect the default, but with custom setting it will make more difficult
Interesting, but if the system has already determined that someone is human then why even present the easy captcha?
The above is a little confusing:
"serve ... legitimate users CAPTCHAs that [are] easy to solve. Bots ... will see CAPTCHAs that are ... difficult ...
you’ll encounter CAPTCHAs that are a breeze ... Bots ... won’t ... see them."
If you can determine in advance who is a bot and who a human, why do you need a CAPTCHA at all?
What's the point of a captcha? To determine if you're a human.
So... if you already know that I'm a human, why show the captcha in the first place?
Unless the recaptcha system is really in place to just decipher the streetview photos of house numbers
btw, to leave this comment, I didn't get a numerical captcha. Am I a machine?
What about the text digitization function that made reCAPTCHA so valuable in the first place?
If the software is capable of differentiating between bots and humans before presenting the captcha, then what is the point of the captcha?
Do I need to make any changes on my web site that uses reCAPTCHA in order to take advantage of these improvements, or are the changes automatic?
How can I get in contact with the team behind SafeBrowsing?
I have a massive list of domains I think SafeBrowsing should include.
I am human but things have not become easier for me :-(
Where do I complain?
http://imgur.com/InqcLyx
How do I enable numeric only recaptcha? It's still showing as letters to me.
This particular user, however, is happy to continue to help decipher scanned texts via reCAPTCHA, even if the computer thinks I'm human.
And obviously, the non-generated numbers are house/mailbox numbers from the Streetview database that Google wants to make semantic.
[EDIT: Solving a ReCAPTCHA to comment on an article about ReCAPTCHAs seems a bit too much of a good thing. :P
1642 utofio. Wavy words are not quite done with, it seems.]
The megatypers Captcha works awesome and pays well so do register and use the invitation code which is mandatory to register.
Invitation CodeS : 7VF1
7VF2
Hi
How can i make it only numeric
we have used it in one site but the alphabets captacha is most of the time unreadable for many users
can you tell the settings how to make it only numeric for making our life easy
Thanks and regards
Parvez
How can I configure the reCaptcha control to use this update? I found the current version is still showing very difficult words to read.
Actually, the captchas are only easier if you have any cookies from Google.
So its actually Google's way of punishing those that don't use their services.
Open up a private browser window and try a captcha, you'll know that they're significantly harder, not even difficult, they just automatically fail.
Actually, the captchas are only easier if you have any cookies from Google. Open up a private browser window, you'll notice that the captchas have black blobs in them and automatically fail.
If you're being tracked by Google's cookies, then the captchas are easier. If you're not being tracked, then its harder.
The example shown shows up on my home Mac using Safari. However, on my Windows PC using Internet Explorer at work I am now seeing words that are even more indecipherable than in the past (two words with a black ink blot over them). This is at the "Public PAIR" page of the USPTO.
so how do we get the new AP?
Woooow you are not even using it for this form, will this might be the answer to my q.
I personally think this is too bad. The point of reCAPTCHA, beside detecting bots, is to improve OCR. Improving OCR for numbers is not that helpful (if that is what it is even doing, but I assume it does not) as improving OCR for letters and other characters.
It was a very nice and helpful idea and this essentially ruins it. :(
OCR has become very advanced, to the point that it reads the distorted letters with better accuracy than some humans.
I'm pretty sure there's still a benefit (Google Street View) from getting the numbers right. As well as preventing bots abusing the system.
So, no, it is not ruined.
I am confused - the text implies that form of captcha (numbers vs. twisted letters) depends on whether or not the system believes I am a human. But if the system already knows if I am a human, BEFORE I am presented a captcha, what is the point of showing it.
Do I understand the term CAPTCHA ("Completely Automated Public Turing test to tell Computers and Humans Apart") in a wrong way?
To me it looks like the (second) numbers are house numbers. So perhaps it will help improve Google Maps?
How to use this new captcha? Like the one being asked in this comment box ?
Hi,
my website always serves the very hard recaptchas. But I'm human!
Why am I always detected as a bot?
Best regards,
--Martin
I run a website for older people, and need to more closely hug the line in allowing bots through versus the clients. Through testing, it seems that if the system ever triggered to think the client is a bot then they would essentially become locked out of the system as the words would be too difficult for them.
reCAPTCHA is not showing good please check this page http://www.topseoforum.com/ucp.php?mode=register
If I'm understanding this correctly, in an attempt to block spam and bots, the captcha will also get increasingly difficult over multiple attempts while being testing by web designers tweaking their code eventually bringing testing to a halt!
Alan, Check out http://techcrunch.com/2012/03/29/google-now-using-recaptcha-to-decode-street-view-addresses/
At first reCaptcha was used to help digitize the 30% of words current OCR tech couldn't solve.
Now that google owns recaptcha they are using it to help decipher google street maps house numbers, street signs and business names.
I don't think it's ruined.
Once reCAPTCHA (wrongly) determines you're a bot, you start being served challenges with two almost impossible to decipher random letter sequences (both of them "control words").
http://i.imgur.com/01F2eES.png
Maybe you think you can read this, but believe me, you can't. I tried "ryntrInt llyHFrv" on this particular one, and it was wrong. And they're all this bad. It takes me an average 10-15 tries to get one of them right, which of course means that I'll never get out of the "hole" of reCAPTCHA thinking that I'm a bot, because I fail so often.
I appreciated getting the easier, Street View captchas while I could still get them. But this adaptivity approach fails badly when going into the other direction (making challenges harder than classical reCAPTCHAs, rather than easier).
From my very limited dataset of just my own encounters, reCAPTCHAs human/bot pre-distinction is atrociously bad. And from my own horrible experiences with it, assuming that many of my own legitimate users will have to deal with the same, I've had no choice but to ditch reCAPTCHA entirely. I cannot afford to subject my users to this torture and scare them away forever. It's gone too far. Especially since I hear that there are bots out there with automatic captcha solvers that have a much better hit rate than myself at this point.
Any way to fix the issue whereby the big reCAPTCHA default logo is displayed, which makes users click on it because it includes a huge circle with arrows that makes people think that is the place to click on to reload a new set?
That logo has always been a big problem in terms of usability because it makes people click on it, rather than on the nearby very similar (but much smaller) reload symbol. I am surprised the issue is still there, as illustrated on top of this post.
Post a Comment